- Cum pot remedia adresa URL trimisă blocată de robotul txt?
- Cum deblochez robotul txt?
- Ce înseamnă blocat de roboți txt?
- Site-ul meu are nevoie de un fișier txt roboți?
- Cum verificați dacă robotul txt funcționează?
- Cum activez robotul txt?
- Ce este robot txt în SEO?
- Respectă Google txt-ul roboților?
- Cum mă asigur că Google nu este blocat?
- Poate Google să acceseze cu crawlere fără roboți txt?
- Cum dezactivez subdomeniul în robotul txt?
- Cum blochez un crawler în robotul txt?
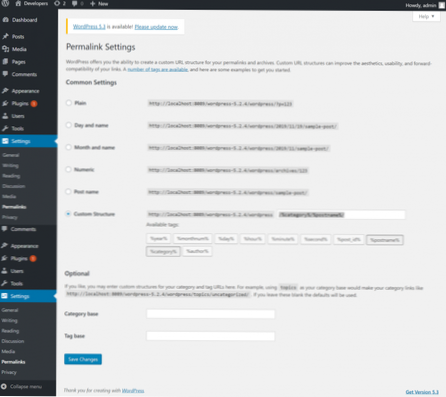
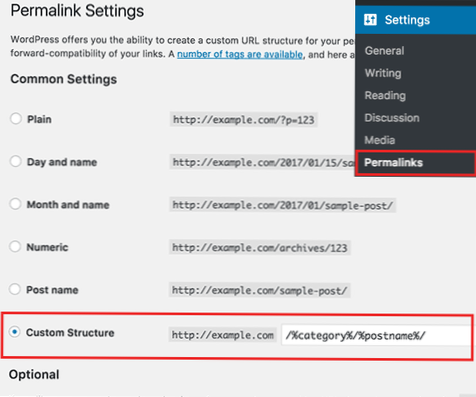
Cum pot remedia adresa URL trimisă blocată de robotul txt?
Actualizați-vă roboții.
txt prin eliminarea sau editarea regulii. De obicei, fișierul se află la http: // www.[numele dvs. de domeniu].com / roboți.txt, totuși, pot exista oriunde în domeniul dvs. Roboții. Instrumentul de testare txt vă poate ajuta să localizați fișierul.
Cum deblochez robotul txt?
Pentru a debloca motoarele de căutare de la indexarea site-ului dvs. web, procedați în felul următor:
- Conectați-vă la WordPress.
- Accesați Setări → Citire.
- Derulați pagina în jos până unde scrie „Vizibilitatea motorului de căutare”
- Debifați caseta de lângă „Descurajează motoarele de căutare să indexeze acest site”
- Apăsați butonul „Salvați modificările” de mai jos.
Ce înseamnă blocat de roboți txt?
Dacă pagina dvs. web este blocată cu un robot. txt, poate apărea în continuare în rezultatele căutării, dar rezultatul căutării nu va avea o descriere și va arăta cam așa. Fișierele imagine, fișierele video, fișierele PDF și alte fișiere non-HTML vor fi excluse.
Site-ul meu are nevoie de un fișier txt pentru roboți?
Majoritatea site-urilor web nu au nevoie de roboți. fișier txt. Acest lucru se datorează faptului că Google poate găsi și indexa toate paginile importante de pe site-ul dvs. Și NU vor indexa automat paginile care nu sunt importante sau nu vor copia versiunile altor pagini.
Cum verificați dacă robotul txt funcționează?
Testați-vă roboții. fișier txt
- Deschideți instrumentul de testare pentru site-ul dvs. și derulați printre roboți. ...
- Introduceți adresa URL a unei pagini de pe site-ul dvs. în caseta de text din partea de jos a paginii.
- Selectați agentul utilizator pe care doriți să îl simulați în lista derulantă din dreapta casetei de text.
- Faceți clic pe butonul TEST pentru a testa accesul.
Cum activez robotul txt?
Pur și simplu introduceți domeniul rădăcină, apoi adăugați / roboți. txt până la sfârșitul adresei URL. De exemplu, fișierul roboților Moz se află la moz.com / roboți.txt.
Ce este robotul txt în SEO?
Roboții. fișierul txt, cunoscut și sub denumirea de protocol sau standard de excludere a roboților, este un fișier text care spune roboților web (cel mai adesea motoarele de căutare) ce pagini de pe site-ul dvs. trebuie să acceseze cu crawlere. De asemenea, le spune roboților web care pagini nu trebuie accesate cu crawlere.
Respectă Google txt-ul roboților?
Google a anunțat oficial că GoogleBot nu va mai asculta de Roboți. directiva txt legată de indexare. Editorii care se bazează pe roboți. Directiva txt noindex are până la 1 septembrie 2019 să o elimine și să înceapă să utilizeze o alternativă.
Cum mă asigur că Google nu este blocat?
Creați o metaetichetă
Iată câteva metaetichete obișnuite pe care le puteți adăuga la paginile dvs. HTML pentru a împiedica apariția anumitor articole de pe site-ul dvs. în Știri Google, blocați accesul la Googlebot-Știri folosind următoarea metaetichetă: <meta name = "Googlebot-News" content = "noindex, nofollow">.
Poate Google să acceseze cu crawlere fără roboți txt?
fișierul txt nu există. Aceasta înseamnă că crawlerele vor presupune, în general, că pot accesa cu crawlere toate adresele URL ale site-ului web. Pentru a bloca accesarea cu crawlere a site-ului, roboții.
Cum dezactivez subdomeniul în robotul txt?
Da, puteți bloca un subdomeniu întreg prin intermediul roboților. txt, cu toate acestea, va trebui să creați un robot. txt și plasați-l în rădăcina subdomeniului, apoi adăugați codul pentru a direcționa roboții să stea departe de conținutul întregului subdomeniu.
Cum pot bloca un crawler în robotul txt?
Dacă doriți să împiedicați ca robotul Google să se acceseze cu crawlere pe un anumit folder al site-ului dvs., puteți introduce această comandă în fișier:
- Utilizator-agent: Googlebot. Disallow: / example-subfolder / User-agent: Googlebot Disallow: / example-subfolder /
- Utilizator-agent: Bingbot. Nu permiteți: / exemplu-subfolder / blocat-pagina. html. ...
- User-agent: * Nu permite: /